Fairgen Check: Your Last Line of Defense Against Bad Data
Published on
November 26, 2025
Written by
Leo Gotheil

Table of contents
Every market researcher has been there. Your data team ran their quality checks. The dataset moved to analysis. Then you spot it during final review: a respondent who claims they "never shop online" but lists Amazon as their favorite retailer. Open-ended responses that sound like ChatGPT. Patterns that don't add up.
You pull the full dataset again. Analysis time becomes another round of manual review. You flag cases, cross-reference answers, debate edge cases. The work is thorough but unstandardized. Different analysts catch different issues.
Even with dedicated quality processes, bad data slips through. And after all that manual work, you're still left wondering: what did we miss
This is why we built Fairgen Check.
The Quality Gap
The research industry is facing unprecedented data quality challenges. In response, the sector has made real progress: better recruiting practices, more sophisticated live checks, and stronger partnerships with quality-focused sample providers.
But these advances focus on prevention. The gap is in detection.
Today's data quality threats are more sophisticated. Professional survey takers have learned to pass attention checks. Bots mimic human behavior. LLMs generate plausible-sounding open-ends that slip through traditional reviews. And the logical contradictions that matter most only become apparent when you understand the full context of a questionnaire.
Finding these issues manually is possible to some extent. But it requires hours that most projects don't have.
An Independent Quality Layer
Fairgen Check acts as a final, automated gatekeeper after data collection. It reviews any dataset, regardless of source or platform, through a system that combines statistical anomaly detection with advanced language models.
Check evaluates data quality across three integrated layers:
Standard Checks: Outlier Detection That Learns
Most tools lean on rigid rules to spot bad respondents. Check takes a different path. It adapts to the patterns inside your actual survey.
Check groups people who answered similarly, then looks for respondents whose behavior breaks from that group. It flags unusual answer patterns, near-duplicate responses between neighbors, speed that’s far faster or slower than the norm for that cluster, and open-ended text that feels copy-pasted or low-effort across multiple questions.
The result is a cleaner dataset where suspicious behavior stands out naturally, without relying on fixed, one-size-fits-all rules.
.gif)
Open-Ended Checks: Fighting LLMs With LLMs
As large language models become widely accessible, the barrier to generating plausible survey responses has dropped to zero. A respondent can now complete open-ended questions in seconds by asking ChatGPT to answer for them.
Check's open-ended layer detects not just obvious problems (gibberish, off-topic rambling, duplicates) but also AI-generated responses that pass casual review. It identifies the linguistic patterns and structural markers that distinguish genuine engagement from generated text.
The goal is to filter out responses that feel AI-generated or inauthentic even when they sound fluent, so your dataset reflects only genuine, thoughtful human input.

Agentic Checks: The Real Revolution
This is where Check becomes fundamentally different.
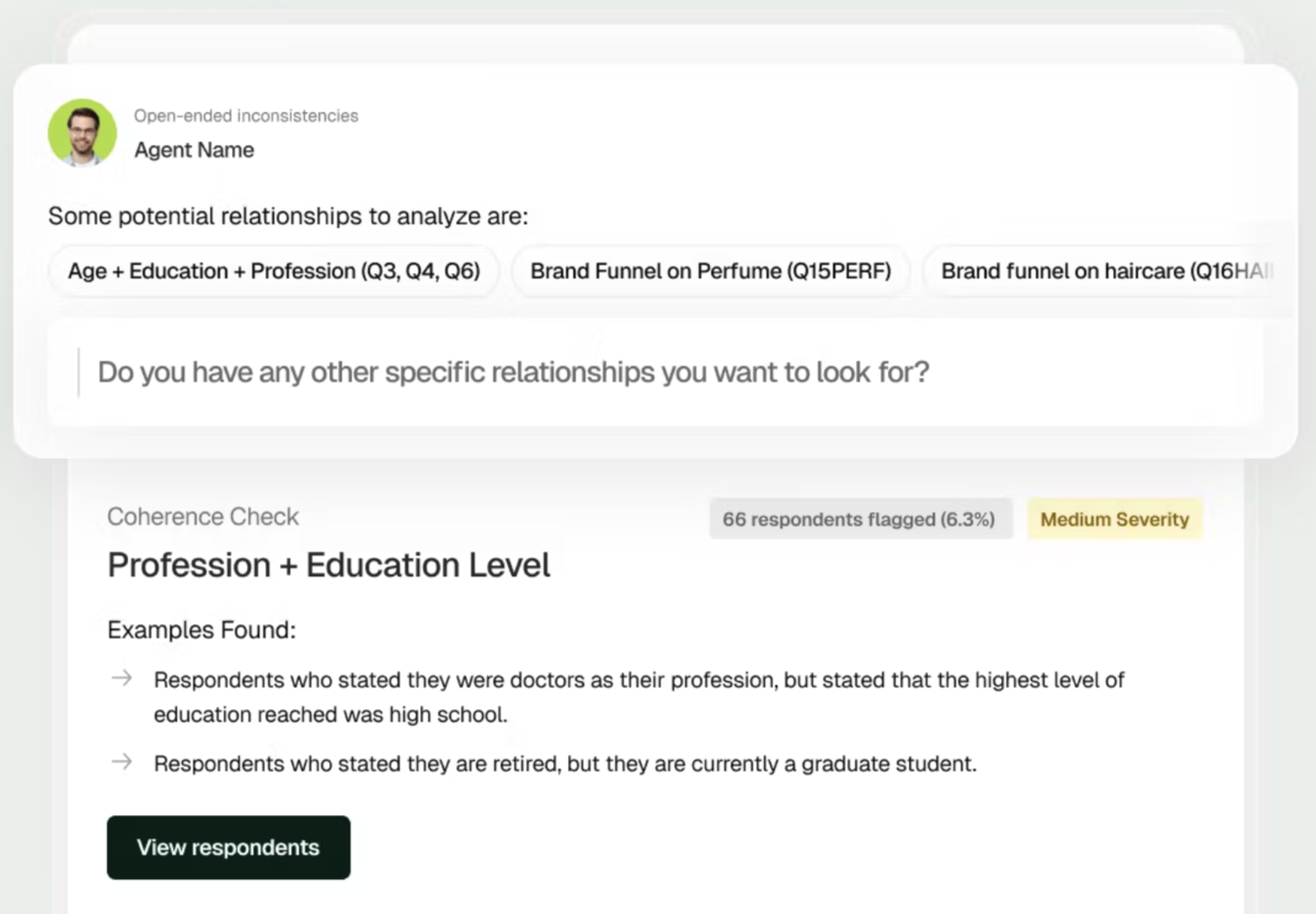
Standard checks flag behavioral anomalies. Open-ended checks assess text quality. But neither can answer: does this respondent's complete set of answers make sense together?
Agentic Checks read your entire questionnaire, not as disconnected questions, but as a coherent instrument with logical relationships. Then they review every respondent's data through that lens, looking for contradictions that only become apparent with full context.
The respondent who reports high brand awareness but can't name a single product. The person who uses a service weekly but can't recall any experience with it. The demographically impossible combinations that slip through standard validation.
These issues would take a senior researcher hours to find manually. Check's agentic system does this for every respondent, on every study, in seconds.
This isn't automation of existing processes. It's a new capability: quality assurance that understands meaning, not just patterns.
Built for Real Research Workflows
Upload your data in any standard format. Check runs all three layers automatically and returns a comprehensive quality scorecard with flagged respondents and clear reasoning. You review what matters, make informed decisions, and move forward with confidence.
The entire process (upload to export) takes minutes, not hours.
Thomas Duhard, Head of Data Projects at Ifop, describes the impact:
"Fairgen Check has enabled us to build faster, more proactive processes to verify data quality in real time, regardless of the source, and to take corrective action earlier to ensure more reliable insights."
This is the shift Check enables: from reactive quality control to proactive quality assurance. From hoping you caught the problems to knowing you did.
What's Next
The launch of Check marks Fairgen's evolution from a breakthrough technology provider to a full platform, one that will see many more releases in the near future.
Data quality evolves as quickly as the bad actors trying to game our systems. Check is built to evolve with it. We're already developing the next generation of detection capabilities and deepening platform integrations.
For researchers managing quality manually, Check represents a fundamental shift. Quality assurance moves from a bottleneck to a baseline. From something you worry about to something you trust.
Because the speed of insights only matters if those insights are right.
Get free access here
Start catching bad data in minutes instead of hours.
Enjoy 14 days of full access — free credits on us.
Every market researcher has been there. Your data team ran their quality checks. The dataset moved to analysis. Then you spot it during final review: a respondent who claims they "never shop online" but lists Amazon as their favorite retailer. Open-ended responses that sound like ChatGPT. Patterns that don't add up.
You pull the full dataset again. Analysis time becomes another round of manual review. You flag cases, cross-reference answers, debate edge cases. The work is thorough but unstandardized. Different analysts catch different issues.
Even with dedicated quality processes, bad data slips through. And after all that manual work, you're still left wondering: what did we miss
This is why we built Fairgen Check.
The Quality Gap
The research industry is facing unprecedented data quality challenges. In response, the sector has made real progress: better recruiting practices, more sophisticated live checks, and stronger partnerships with quality-focused sample providers.
But these advances focus on prevention. The gap is in detection.
Today's data quality threats are more sophisticated. Professional survey takers have learned to pass attention checks. Bots mimic human behavior. LLMs generate plausible-sounding open-ends that slip through traditional reviews. And the logical contradictions that matter most only become apparent when you understand the full context of a questionnaire.
Finding these issues manually is possible to some extent. But it requires hours that most projects don't have.
An Independent Quality Layer
Fairgen Check acts as a final, automated gatekeeper after data collection. It reviews any dataset, regardless of source or platform, through a system that combines statistical anomaly detection with advanced language models.
Check evaluates data quality across three integrated layers:
Standard Checks: Outlier Detection That Learns
Most tools lean on rigid rules to spot bad respondents. Check takes a different path. It adapts to the patterns inside your actual survey.
Check groups people who answered similarly, then looks for respondents whose behavior breaks from that group. It flags unusual answer patterns, near-duplicate responses between neighbors, speed that’s far faster or slower than the norm for that cluster, and open-ended text that feels copy-pasted or low-effort across multiple questions.
The result is a cleaner dataset where suspicious behavior stands out naturally, without relying on fixed, one-size-fits-all rules.
Open-Ended Checks: Fighting LLMs With LLMs
As large language models become widely accessible, the barrier to generating plausible survey responses has dropped to zero. A respondent can now complete open-ended questions in seconds by asking ChatGPT to answer for them.
Check's open-ended layer detects not just obvious problems (gibberish, off-topic rambling, duplicates) but also AI-generated responses that pass casual review. It identifies the linguistic patterns and structural markers that distinguish genuine engagement from generated text.
The goal is to filter out responses that feel AI-generated or inauthentic even when they sound fluent, so your dataset reflects only genuine, thoughtful human input.
Agentic Checks: The Real Revolution
This is where Check becomes fundamentally different.
Standard checks flag behavioral anomalies. Open-ended checks assess text quality. But neither can answer: does this respondent's complete set of answers make sense together?
Agentic Checks read your entire questionnaire, not as disconnected questions, but as a coherent instrument with logical relationships. Then they review every respondent's data through that lens, looking for contradictions that only become apparent with full context.
The respondent who reports high brand awareness but can't name a single product. The person who uses a service weekly but can't recall any experience with it. The demographically impossible combinations that slip through standard validation.
These issues would take a senior researcher hours to find manually. Check's agentic system does this for every respondent, on every study, in seconds.
This isn't automation of existing processes. It's a new capability: quality assurance that understands meaning, not just patterns.
Built for Real Research Workflows
Upload your data in any standard format. Check runs all three layers automatically and returns a comprehensive quality scorecard with flagged respondents and clear reasoning. You review what matters, make informed decisions, and move forward with confidence.
The entire process (upload to export) takes minutes, not hours.
Thomas Duhard, Head of Data Projects at Ifop, describes the impact:
"Fairgen Check has enabled us to build faster, more proactive processes to verify data quality in real time, regardless of the source, and to take corrective action earlier to ensure more reliable insights."
This is the shift Check enables: from reactive quality control to proactive quality assurance. From hoping you caught the problems to knowing you did.
What's Next
The launch of Check marks Fairgen's evolution from a breakthrough technology provider to a full platform, one that will see many more releases in the near future.
Data quality evolves as quickly as the bad actors trying to game our systems. Check is built to evolve with it. We're already developing the next generation of detection capabilities and deepening platform integrations.
For researchers managing quality manually, Check represents a fundamental shift. Quality assurance moves from a bottleneck to a baseline. From something you worry about to something you trust.
Because the speed of insights only matters if those insights are right.
Get free access here
Start catching bad data in minutes instead of hours.
Enjoy 14 days of full access — free credits on us.
Subscribe to our newsletter
Learn more about Fairgen
.png)
.jpg)



